
Prelude:
AiCloudPods has been working with a multi-national investment bank and have been instrumental in the bank’s migration to the cloud and cloud-native app development.
The investment bank has a global market department and AiCloudPods had been tasked to build a big data analytics pipeliene for the Change data Capture.
Change data capture (CDC) is the process of capturing changes made at the data source and applying them throughout the enterprise. CDC minimizes the resources required for ETL ( extract, transform, load ) processes because it only deals with data changes. The goal of CDC is to ensure data synchronicity.
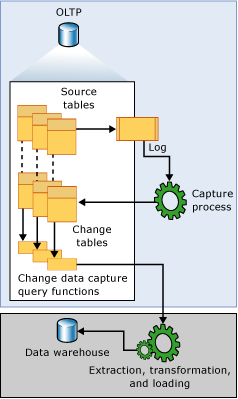
A Data Warehouse (DWH) must maintain the history of business measure changes. Thus, the ETL processes of the Data Warehouse loading must be able to detect the data changes which have occurred in source operation systems during the business operations.
Inserting new records, updating one or more fields of existing records, deleting records are the types of changes which Change Data Capture processes must detect in the source system.
What Happened on 2016:
The story began at 2016. The investment bank had implemented the SCOOP mechanism to bring the RDBMS data onto their Big Data ecosystem running in Microsoft Azure.
With AiCloudPods as a reputed consultancy in the AI, Cloud and Kubernetes space, the investment firm asked us to improve their solution. AiCloudPods took that as a challenge and implemented the CDC solution on Azure platform. The solution architecture is as below.
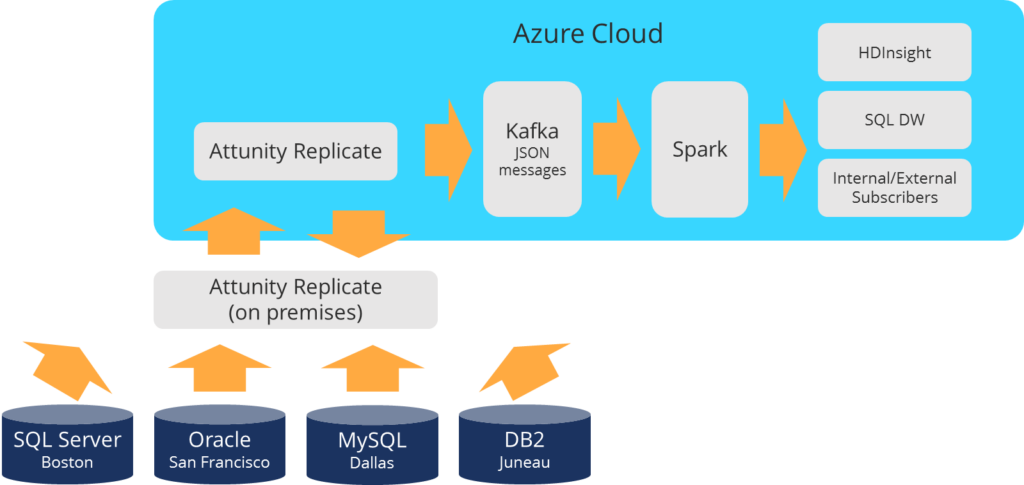
What unfolded on 2016:
The story unfolded at the summer of 2016. AiCloudPods being a DevOps oriented firm identified the CDC solution based on the white paper from Hortonworks.

The four step steps in the white paper proved to be a market leader strategy and we would like to explain them here. The CDC solution has been explained in the Azure Databricks Notebook.
Step 1: Define the case classes:

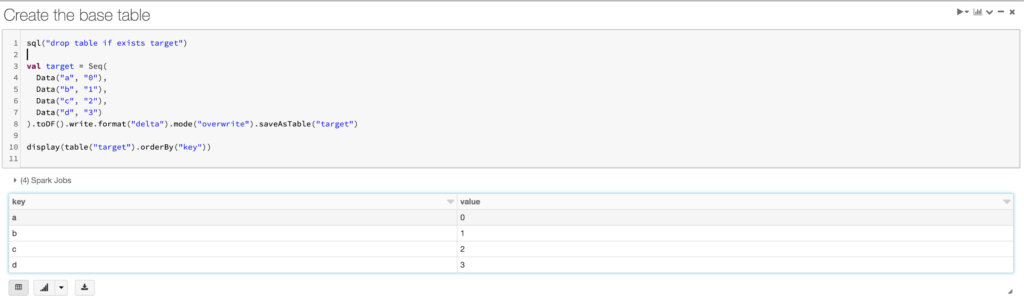
Step 2: Create the base table
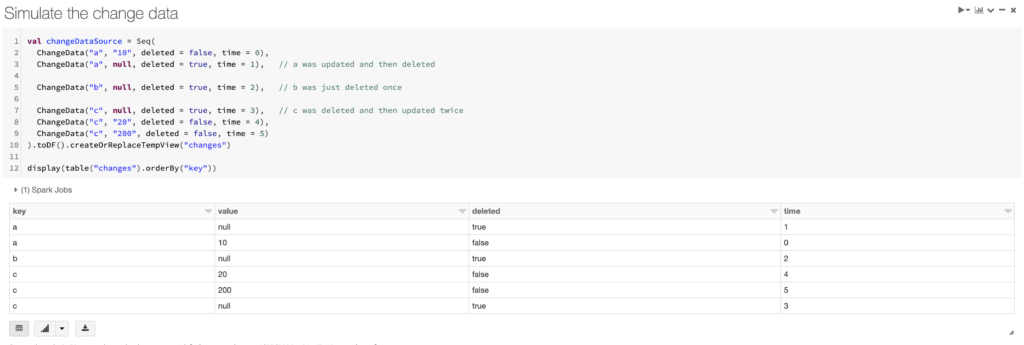
Step 3: Simulate the change data
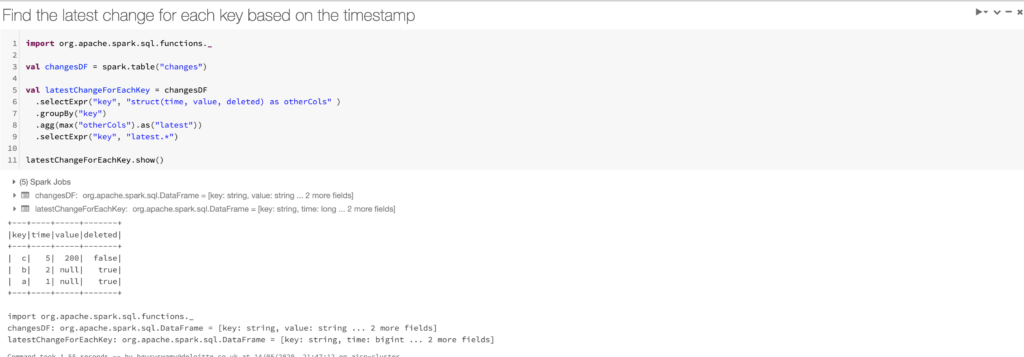
Step 4: Find the latest change for each key based on the timestamp
Step 5: Build the incremental table with delta changes

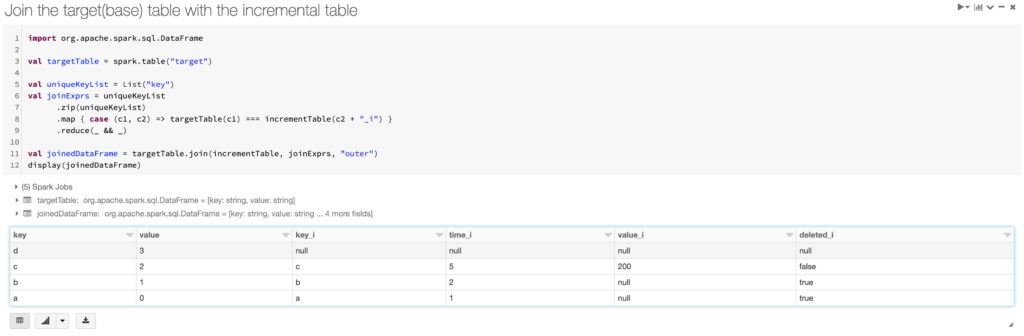
Step 6: Join the target(base) table with the incremental table
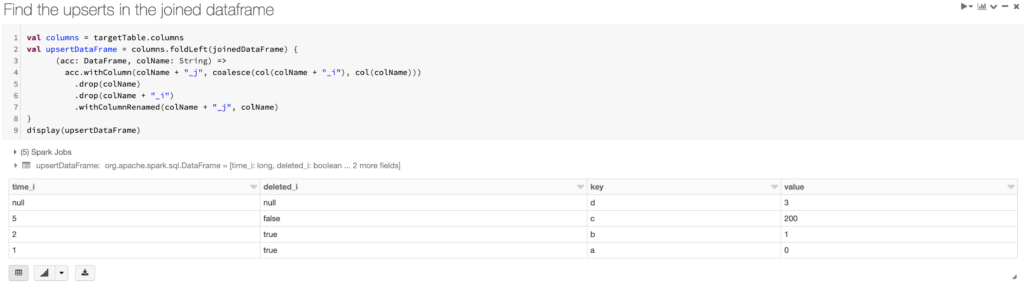
Step 7: Find the upserts in the joined dataframe
Step 8: Remove the deletes from the upsert dataframe

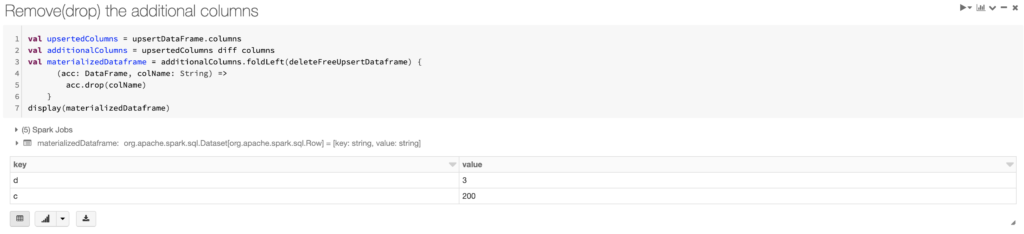
Step 9: Remove(drop) the additional columns
Step 10: Replace the base(target) table with the reconciled data using temp table
Keys “a” and “b” were effectively deleted, “c” was updated, and “d” remains unchanged
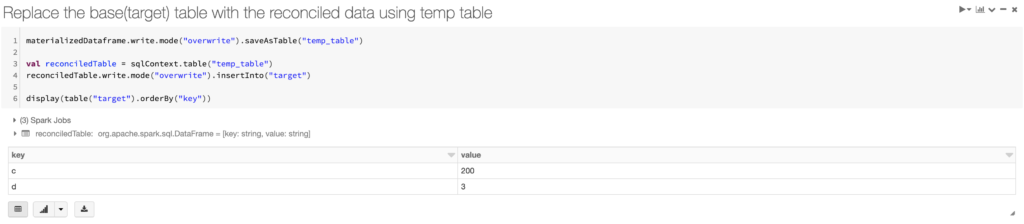
The four-step strategy explained above went live in the late 2016 and since worked over 4PB of data in the investment bank’s data lake. The solution had been a huge success on the global markets department and since used on multiple departments like Finance, Risk, Assets & Retail.
What Happened on 2019:
After three years of successful stint the CDC solution has been revamped after the introduction of Delta Lake from Databricks.
Delta Lake is an open source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
Delta Lake on Databricks allows you to configure Delta Lake based on your workload patterns and provides optimised layouts and indexes for fast interactive queries. The below is a quote from the Databricks.
Change data capture (CDC) is a type of workload where you want to merge the reported row changes from another database into your database. Change data come in the form of (key, key deleted or not, updated value if not deleted, timestamp).
You can update a target Delta table with a series of ordered row changes using MERGE and its extended syntax support. This notebook illustrates change data capture using the extended MERGE syntax (i.e. support for delete, conditions in MATCHED and NOT MATCHED clauses).
What Unfolded on 2019:
With the introduction of extended merge, the CDC becomes simpler and easier to implement and AiCloudPods used the opportunity to revamp the Hortonworks four-step strategy solution we have seen above.
We would implement the same process as above in Databricks Delta. The first four steps are same as they form the simulation for the CDC scenario. Once we are done with the Step 4 which is Find the latest change for each key based on the timestamp, we would take a detour and implement the exact same solution in the Databricks Delta Lake.
Step 5: Apply Extended merge in Delta table for CDC
Keys “a” and “b” were effectively deleted, “c” was updated, and “d” remains unchanged
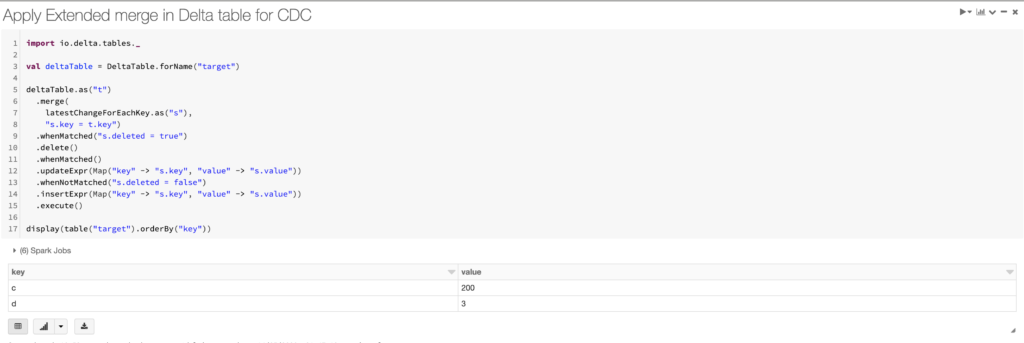
As we could clearly notice, the Databricks Delta lake massively simplifies the CDC solution from 10 steps in the above example to just 5 steps with 4 steps as Simulation setup. That effectively leaves us with only one step for CDC implementation and Databricks does the heavy-lifting under the hood and makes our life easier.
Delta Lake offers the below.
- ACID transactions on Spark: Serializable isolation levels ensure that readers never see inconsistent data.
- Scalable metadata handling: Leverages Spark’s distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease.
- Streaming and batch unification: A table in Delta Lake is a batch table as well as a streaming source and sink. Streaming data ingest, batch historic backfill, interactive queries all just work out of the box.
- Schema enforcement: Automatically handles schema variations to prevent insertion of bad records during ingestion.
- Time travel: Data versioning enables rollbacks, full historical audit trails, and reproducible machine learning experiments.
- Upserts and deletes: Supports merge, update and delete operations to enable complex use cases like change-data-capture, slowly-changing-dimension (SCD) operations, streaming upserts, and so on.
AiCloudPods is making most of the above features to enable our clients having a sleek and lightning-fast data analytics pipelines in Cloud and On-Premises.
Let us know for more information on how to improve your pipelines or to migrate them to Cloud or to build one in Cloud. We would offer the demo notebooks with our solution and we will build a pipeline just like the one discussed in the blog here.