
In this blog post, we will look at the effective way of creating a data lake in a serverless manner. In the cloud data analytics world, we always face the humongous task of estimating the data volume and identifying the server capacity accordingly. For a large enterprise with individual teams responsible for capacity planning, design decision group, architecture and data modelling the engineers could get away with the server provisioning. However for a mid or small sized team, the serverless architecture for a data lake would be a boon.
AWS provides the serverless components which we require for our data lake and we will see how we can piece them together. The point that stands out in the architecture is little/few lines of coding. The resources in the architecture would do the heavy lifting for us and we would configure them in such a fashion that the resources are in steroids.
The architecture is an event based one and this can be tweaked a bit to make work for the batch. We will tweak at the blog and let’s jump into the Serverless data lake.
Let’s have a quick overview of the resources we chain together.
Amazon Kinesis Data Stream: Real-time data streaming service.
Amazon Kinesis Delivery Stream(Firehose): Real-time data delivery service
Amazon Lambda: Serverless compute
Amazon S3: Object storage
Amazon Glue & Crawler: Fully managed ETL and schema identifier
Amazon Athena: Interactive query service
Amazon QuickSight: Business Intelligence Service(Dashboarding)
Let’s put a magnifying glass on us and look into the resources we will chain together at the end of the blog.
Amazon Kinesis Data Stream:
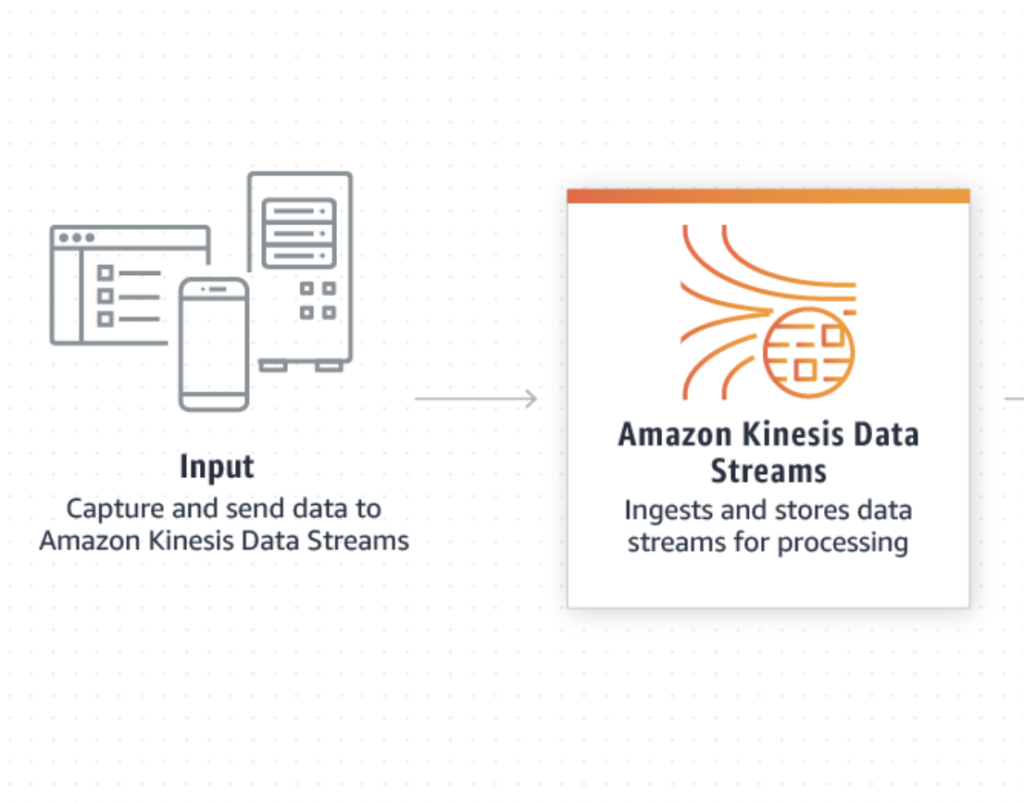
- Amazon Kinesis would store the data for a certain period of time which is called Data Retention Period. We usually choose the 168 hours(7 days).
- The encryption can be enabled. The server-side encryption with the AWS managed keys are simple to start with.
- The most important feature is in the Kinesis data stream is the Shard size and there is a Shard Calculator for us to estimate the value. We would most probably stick with ‘1’ as each shard ingests upto 1 MiB/second and 1000 records/second and emits up to 2 MiB/second.
Amazon Kinesis Delivery Stream (Firehose):
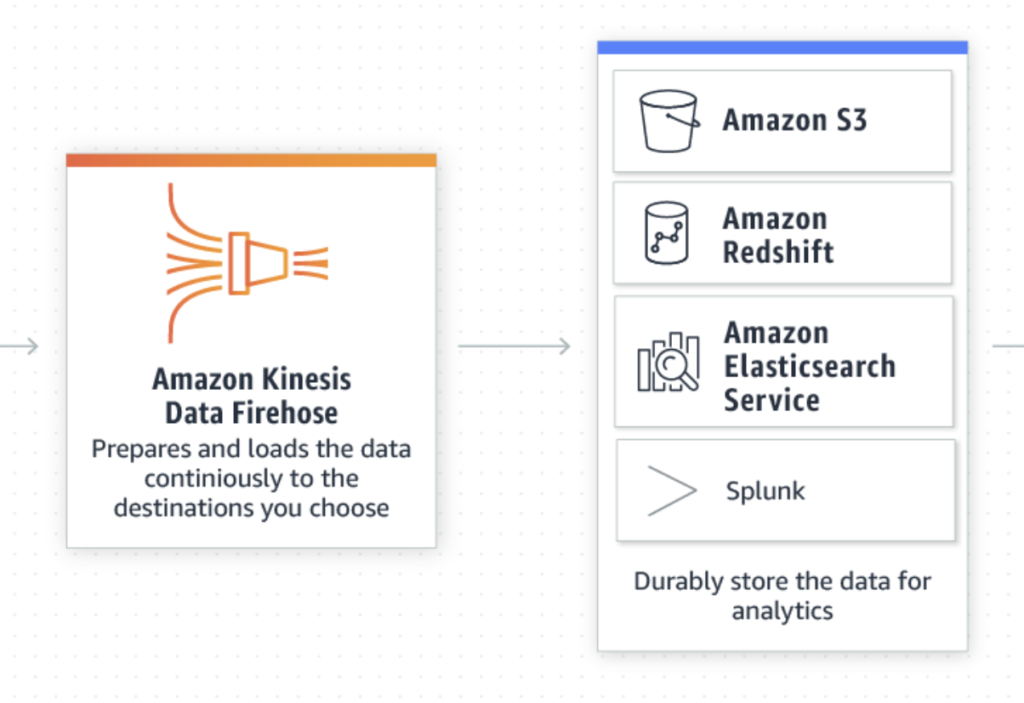
- Kinesis delivery stream loads the streaming data into data lakes, data stores and analytics tools.
- Firehose listens to the events flowing into the Kinesis Data stream and sinks the data into our Data Lake — S3.
- Firehose requires the Source(data stream) and Destination(S3) in the configuration.
- The source records can be transformed on the transit and a lambda function can be inserted and gets executed for the transformation.
- The source records format can be modified to Apache Parquet and they would help massively for our querying engine.
- We could add a back up in Firehose configuration as we look to transform the data in transit. Firehose provides the RAW data onto the source records and we can replay the messages if we encounter an error while transforming the data or the pipeline gets corrupted.
- Firehose provides an opportunity over compaction or buffer conditions on landing the data. This can be either Time limited(MiB) or Size limited(Seconds).
- The nagging issue in the firehose is the ‘NEWLINE’. While we compact the data on Time or Size the events would be appended to each other in the parquet file. All the events would be written as a single line and we would end up having only one record per buffer.
- To overcome this limitation, we add the data transformation in transit using a lambda function. The lambda would add a newline after every event. We could add a newline character in the events while we write the event on data stream(at source level). However we usually don’t want to do this and so a lambda function would be required.
Amazon Lambda
- The lambda function adds the newline to the Kinesis record and helps eliminate the NO-NEWLINE issue in Kinesis Firehose.
for record in event['records']:
payload = base64.b64decode(record['data'])
# Do custom processing on the payload here
payload = payload + '\n'
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(json.dumps(payload))
}
output.append(output_record)
return {'records': output}
Amazon S3:
- The S3 is our Data Lake and the format would be Parquet.
- We usually compress the data using Snappy Algorithm and while landing the data using Kinesis Firehose, this compression can be configured.
- The data can been partitioned on the S3 bucket and Firehose provides the partition granularity to the hour.
year=!{timestamp:yyyy}/month=!{timestamp:MM}/date=!{timestamp:dd}/hour=!{timestamp:HH}
- The data in rest can be encrypted and as usual we pick the AWS managed keys for the server side encryption.
Amazon Glue & Crawler
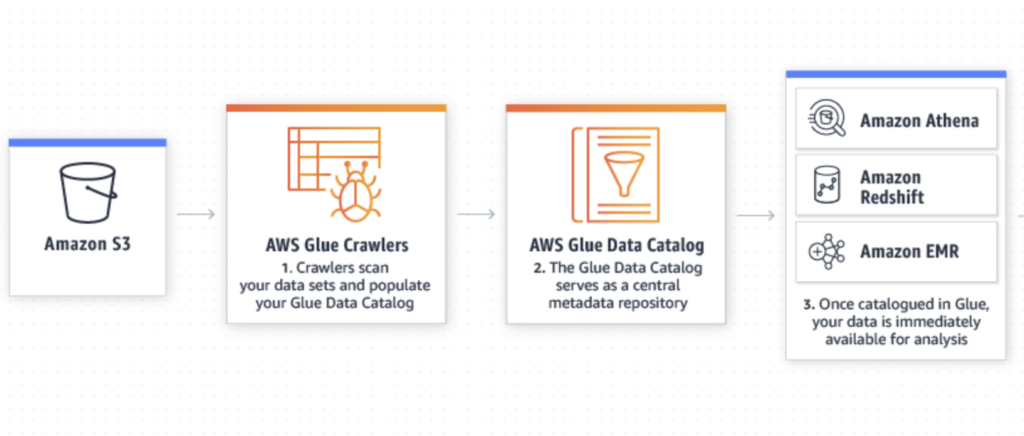
- The data in the S3 are in flat files and needs to be queried for the analytics purposes to extract meaningful insights.
- The schema of the files residing in S3 can be easily identified and the Glue is the adhesive for this process.
- Glue Crawler run on the S3 buckets and the stored files and extracts the schema. The extracted schema would then registered as table in Glue.
- The table is called Data Catalog Table and it is visible across the querying engines — Athena & Redshift.
- The crawlers are responsible for identifying the newer partitions in the S3 bucket and they can be scheduled according to the granularity of the partitioning.
- The partitioning can be per day or per hour and scheduling of the Glue Crawler should fall in line with that.
- There are multiple config options in Glue Crawler like Schema evolution t and the Object deletion.
Amazon Athena:
- Athena is a an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL.
- Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
- The data catalog tables created by the Glue crawlers are automagically visible in Athena and help us in querying the data in S3.
- Athena is out-of-the-box integrated with AWS Glue Data Catalog, allowing you to create a unified metadata repository across various services, crawl data sources to discover schemas and populate our Catalog with new and modified table and partition definitions, and maintain schema versioning.
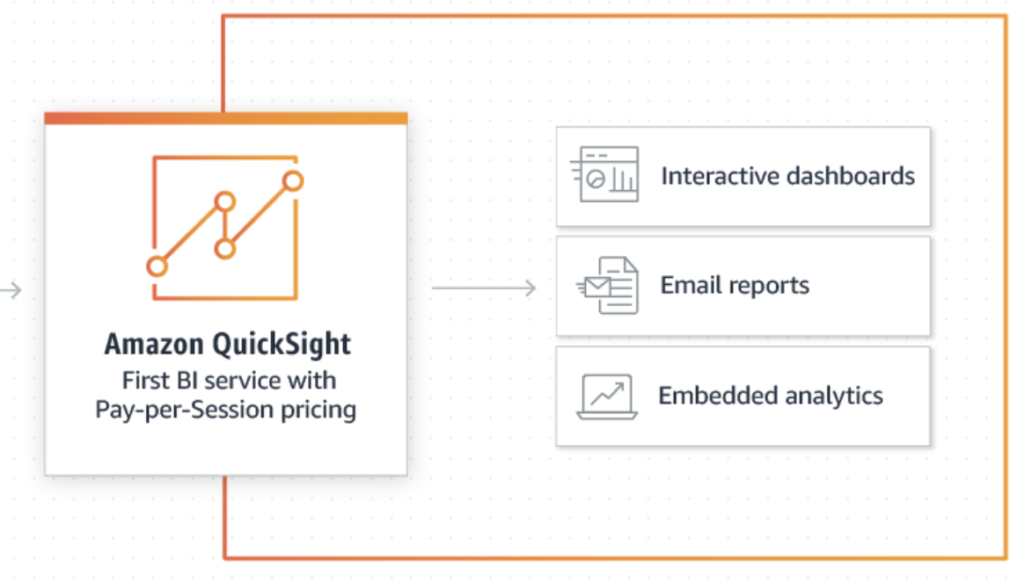
- Amazon QuickSight is a fast, cloud-powered business intelligence service that makes it easy to deliver insights to everyone in your organisation.
- As a fully managed service, QuickSight lets you easily create and publish interactive dashboards that include ML Insights. Dashboards can then be accessed from any device, and embedded into your applications, portals, and websites.
- With our Pay-per-Session pricing, QuickSight allows you to give everyone access to the data they need, while only paying for what you use.
Serverless Architecture:
Let’s chain the resources discussed above and we would end up having a nice architecture as below.
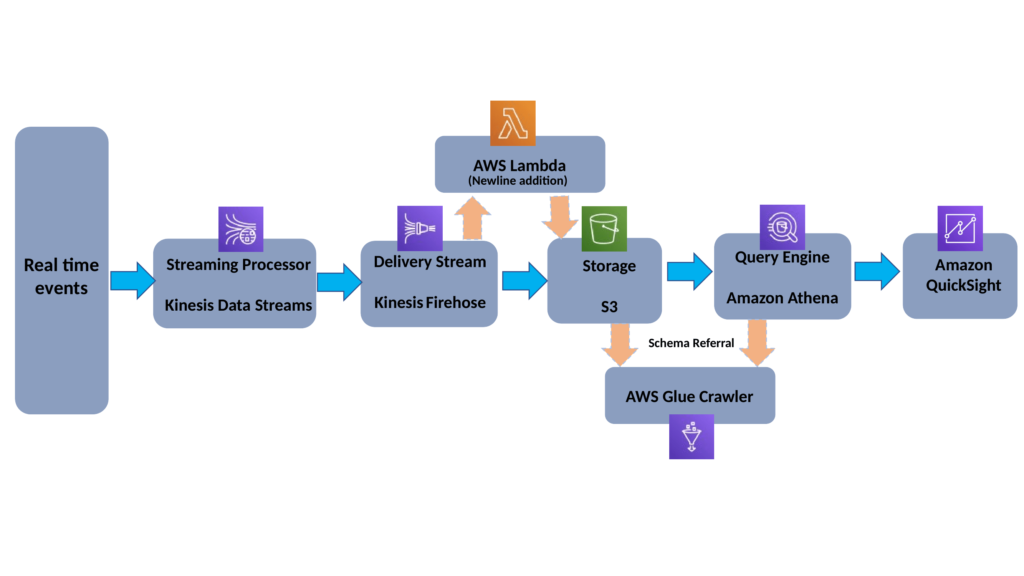
The below are the benefits we get from the serverless data architecture.
- Low/No infrastructure to maintain.
- Low cost
- Easy to engineer
- Easy to understand
Batch pipeline Tweak:
The above pipeline can be retrofitted for the batch with a trigger. The CloudWatch trigger or Lambda trigger can be set for the batch data creation and the data can be sent to the Kinesis data stream. Once it reaches the data stream, the serverless pipeline would kick off and the data can be queried for dashboarding purposes.
About Us:
We are a Cloud-First Consultancy with Kubernetes & AI Expertise. Our diverse teams of experts combine innovative thinking and breakthrough use of technologies to progress further, faster. From the C-suite to the front line, we partner with our clients to transform their organizations in the ways that matter most to them.